配置了三天整的环境,终于让我把这个框架玩明白了,遇到的错误在网上到处都找不到,终于在周末找到了我配置环境错误的原因!
环境安装
在使用SwinTransformer的时候,不能按照SwinTransformer的github里的get_start.md进行安装,否则安装的mmdetection在运行SwinTransformer的时候会报错找不到”embed_dim”这个参数,即使注释掉模型里的这个参数,也会报别的错误。
官方的安装方式如下
官方安装环境和我这篇博客内容差不多:
实际上,我们安装使用SwinTransformer的时候可以参考一部分官方文件。以下是安装过程:
基础环境:
-
python 3.6+
-
pytorch 1.3+
-
CUDA 9.2+
-
GCC 5+
-
MMCV
其中需要注意的是,MMCV版本要和MMDetectron版本对应,而SwinTransformer使用的2.11.0,所以MMCV版本要大于1.2.4,小于1.4.0。
以下是部分对照表:
| MMDetection version | MMCV version |
|---|---|
| master | mmcv-full>=1.2.4, <1.4.0 |
| 2.11.0 | mmcv-full>=1.2.4, <1.4.0 |
| 2.10.0 | mmcv-full>=1.2.4, <1.4.0 |
| 2.9.0 | mmcv-full>=1.2.4, <1.4.0 |
| 2.8.0 | mmcv-full>=1.2.4, <1.4.0 |
| 2.7.0 | mmcv-full>=1.1.5, <1.4.0 |
| 2.6.0 | mmcv-full>=1.1.5, <1.4.0 |
| 2.5.0 | mmcv-full>=1.1.5, <1.4.0 |
| 2.4.0 | mmcv-full>=1.1.1, <1.4.0 |
| 2.3.0 | mmcv-full==1.0.5 |
| 2.3.0rc0 | mmcv-full>=1.0.2 |
| 2.2.1 | mmcv==0.6.2 |
| 2.2.0 | mmcv==0.6.2 |
| 2.1.0 | mmcv>=0.5.9, <=0.6.1 |
| 2.0.0 | mmcv>=0.5.1, <=0.5.8 |
首先,我们需要安装CUDA和PyTorch。这里的版本可以参照我的另外两篇博客:
在进行测试时,同样需要安装apex和timm库,而timm库使用
pip install timm
进行安装
1.Pytorch安装
在安装pytorch的时候尽量选择到官方网站进行选择安装
例如:
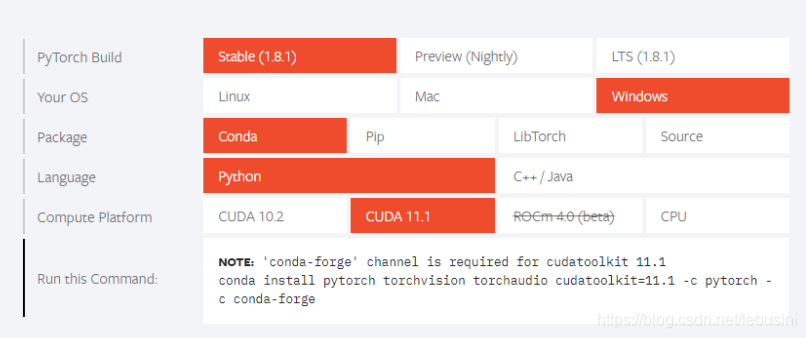
输入安装:
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c conda-forge
或者
pip install torch==1.10.0+cu111 torchvision==0.11.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
2.mmcv-full安装
这里和《Linux安装mmcv和mmdetection踩坑》安装过程是一样的
3.MMDetection安装
这里就不要根据官方安装方式安装,我们直接先下载Swin-Transformer-Object-Detection的代码
git clone https://github.com/SwinTransformer/Swin-Transformer-Object-Detection.git
进入文件夹
pip install -r requirements/build.txt
pip install -v -e .
如此就可以安装配置好了。
这里需要注意的是官方的Swin-Transformer-Object-Detection的数据集都是基于mask rcnn的,数据集和一般不一样。
下面是带有mask的数据集训练出来后的模型结果:

个人数据集训练修改
有篇博客讲得很详细。原文链接
在”Swin-Transformer-Object-Detection-master/configs/swin/”目录下,可以看到模型文件,选择对应的修改
以”cascade_mask_rcnn_swin_base_patch4_window7_mstrain_480-800_giou_4conv1f_adamw_3x_coco.py”为例:
必要修改:num_classes
选择修改:norm_cfg,optimizer,runner,optimizer_config
# head为例
roi_head=dict(
bbox_head=[
dict(
type='ConvFCBBoxHead',
num_shared_convs=4,
num_shared_fcs=1,
in_channels=256,
conv_out_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=15, # 修改类别数量
# 根据gpu的数量,使用合适的BN
# norm_cfg=dict(type='SyncBN', requires_grad=True),
norm_cfg=dict(type='BN', requires_grad=True),
# 调整学习率等相关参数,lr = 0.00125*batch_size
optimizer = dict(
_delete_=True,
type='AdamW', lr=0.00125,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(
custom_keys={'absolute_pos_embed':
dict(decay_mult=0.),
'relative_position_bias_table': dict(decay_mult=0.),
'norm': dict(decay_mult=0.)}))
# 修改epoch并将“EpochBasedRunnerAmp“改为”EpochBasedRunner“
runner = dict(type='EpochBasedRunner', max_epochs=36)
# 不适用fp16,将use_fp16改为False
fp16 = None
optimizer_config = dict(
type="DistOptimizerHook",
update_interval=1,
grad_clip=None,
coalesce=True,
bucket_size_mb=-1,
use_fp16=False,
)
在”configs/base/datasets/coco_instance.py”中根据需要修改
必要修改:data_root,ann_file,img_prefix
选择修改:img_size,samples_per_gpu,workers_per_gpu(多GPU训练时修改)
# 修改数据集的类型,路径
dataset_type = 'CocoDataset'
data_root = '/home/coco/'
# 修改img_size等参数,CUDA out of memory时可以修改
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
# 原本为1333*800
#dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='Resize', img_scale=(416, 416), keep_ratio=True),
# 修改batch_size
data = dict(
samples_per_gpu=1, # 每块GPU上的sample个数,batch_size = gpu数目*该参数
workers_per_gpu=1, # 每块GPU上的workers的个数
# 以train为例
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json', # 标注路径
img_prefix=data_root + 'train2017/', # 训练图片路径
pipeline=train_pipeline),
修改类别:mmdet/datasets/coco.py
class CocoDataset(CustomDataset):
# 数据分类类别
CLASSES = ('person', 'tool_vehicle', 'bicycle', 'motorbike', 'pedal_tricycle', 'car', 'passenger_car',
'truck', 'police_car', 'ambulance', 'bus', 'dump_truck', 'tanker', 'roadblock', 'fire_car')
mmdet/core/evaluation/class_names.py文件
def coco_classes():
return ['person', 'tool_vehicle', 'bicycle', 'motorbike', 'pedal_tricycle', 'car', 'passenger_car',
'truck', 'police_car', 'ambulance', 'bus', 'dump_truck', 'tanker', 'roadblock', 'fire_car']
模型预训练,权重加载、保存参数,config/base/default_runtime.py文件
checkpoint_config = dict(interval=1) # 每训练一个epoch,保存一次权重
load_from = None # 加载backbone权重
resume_from = None # 继续训练
修改”./tools/train.py”文件
# 选取其中一种版本,单机版本 MMDataParallel、分布式(单机多卡或多机多卡)版本 MMDistributedDataParallel,一般用default='none'
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
训练模型,使用编号为3的单个gpu训练
后台运行:
nohup python -u test.py > test.log 2>&1 &
python ./tools/train.py \
configs/swin/cascade_mask_rcnn_swin_base_patch4_window7_mstrain_480-800_giou_4conv1f_adamw_3x_coco.py --gpu-ids 3
使用4个gpu训练
tools/dist_train.sh \
configs/swin/cascade_mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_giou_4conv1f_adamw_3x_coco.py 4
指定gpu测试
export CUDA_VISIBLE_DEVICES=1 tools/test.py config/swin/cascade_mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_giou_4conv1f_adamw_3x_coco.py \
[checkpoint] --eval bbox