在此记录学习Tesla自动驾驶的多源目标检测的过程,便于今后的研究工作。
此处学习的是来自知乎的一篇关于Tesla多视角目标检测的文章,通过自己的理解总结出我自己学习的博客内容。之后我去寻找的相关论文的学习也会继续总结。

Tesla的视觉系统由8个摄像头环绕车身,分为前视3目,负责近,中远3种不同距离和视角的感知;侧后方两目,侧前方两目,以及后方单目,完整覆盖360度场景,通过神经网络的转换之后,利用所得信息建立一个三维向量空间(Vector Space),用于汽车的路线规划和智能驾驶。
下面是基本的模型结构:
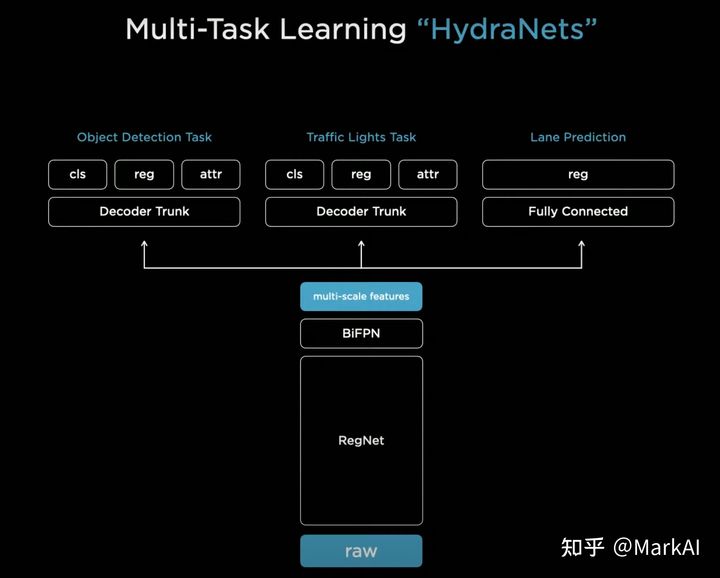
RegNet作为Backbone,使用BiFPN构建多尺度特征图,在特征图的基础上,分为三个子任务,分别是目标检测、交通灯识别、道路预测。
共享Backbone和BiFPN能够在部署的时候很大程度的节省算力,使用这样的结构有以下三个好处:
1、预测的时候非常高效:因为共享特征,避免了大量的重复计算;
2、可以解耦每个子任务:每个子任务可以在backbone的基础上进行fine-tuning,或是修改,而不影响其他子任务。
3、可以加速fine-tuning(微调):训练过程中可以将feature缓存,这样fine-tuning的时候可以只使用缓存的feature来fine-tune模型的head,而不再需要重复计算。
融合方法
多视角相机的作用就是将上述网络的预测结果转换到三维空间中的车体坐标系下。三种融合的可能方案:
方案1:
在各个摄像头上分别做感知任务,然后投影到车体坐标系下进行整合;(图像空间的输出并不是正确的输出空间,需要精确到像素级别的预测才能较准确投影到三维向量空间,但要求过于严格)
方案2:
将多个摄像头的图像直接变换和拼接到车体坐标系下,再在拼接后的图像上做感知任务;(图像完美地拼接本身就是非常困难的事,且会受到路面状况的影响。)
方案3:
直接端到端处理,输入多相机图像,输出车体坐标下的感知结果;(Tesla选择的方案)
Tesla采用的端到端网络:
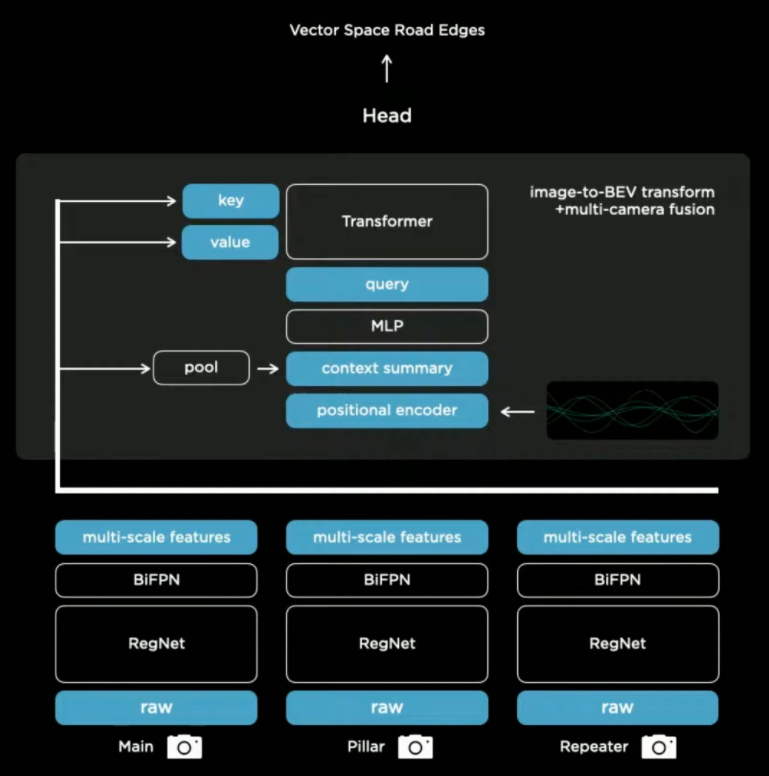
将多视角图像输入到之前提到的网络当中,并将输出的特征图通过transformer转换为Key和Value,在之后的子任务当中,通过查表的方式用于预测,实现了多视角端到端。
其中,Tesla还加入了时序信息,暂时和我的工作相关性不大,就不记录了。